Notatki z analizy raportu Measuring Agents in Production opublikowanego na początku grudnia (2025). Zachęcam do samodzielnej analizy raportu – nie zamierzam go przepisywać. Pozwolę sobie jednak po nim poskakać, bo nie do końca pasuje mi jego kolejność, ale też mam kilka własnych obserwacji.
Zacznijmy od wprowadzenia – W roku 2024 i 2025 widać zdecydowaną zmianę w sposobie tworzenia oprogramowania, oczywiście chodzi o masowe wykorzystanie LLM w procesie. Pojęcie “Agenta AI” – systemu zdolnego do autonomicznego planowania, korzystania z narzędzi i wykonywania wieloetapowych zadań – stało się istotnym punktem zainteresowania w badaczy ale też biznesu i pojawia się w strategii największych korporacji technologicznych. Natomiast poza teorią i budowaniem strategii, jest też prktyka i w tym badaniu właśnie mamy okazję spojrzeć na kontekst oceny wdrożeń środowisk agentowych, dowiedzieć się trochę więcej jak takie systemy są budowane oraz jaką przynoszą wartość biznesową.
Żeby nie było bardzo entuzjastycznie, zacznijmy od ogólnego otoczenia i tutaj rzeczywistość wdrożeniowa jest brutalna. Badania rynkowe, w tym raporty MIT i Gartnera, wskazują na alarmująco wysoki wskaźnik awaryjności. Szacuje się, że nawet 95% wdrożeń agentów kończy się niepowodzeniem lub nie wychodzi poza fazę PoC. Projekty te często upadają z powodu kosztów, braku przewidywalności, halucynacji modeli lub niemożności zintegrowania ich z istniejącą infrastrukturą.
W tym kontekście badanie to badanie które analizujemy jest kluczowe, ponieważ nie skupia się na teoretycznych możliwościach, ale na konkretnych danych z udanych wdrożeń. Analizuje praktyki inżynierskie, które pozwoliły 86 systemom produkcyjnym przetrwać zderzenie z rzeczywistością.
Przejdźmy do samego badania
Dlaczego biznes wdraża agentów?
Wbrew narracjom o Artificial General Intelligence (AGI) czy autonomicznych bytach, firmy wdrażają agenty w bardzo konkretnym celu: zwiększenia efektywności operacyjnej. Pozostałe cele zostały ujęte na poniższym wykresie:
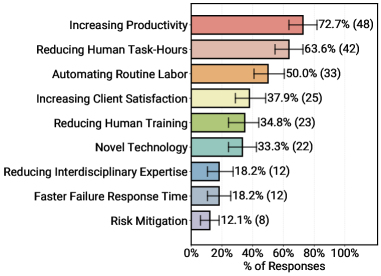
Tutaj małe zaskoczenie: niski wynik “mitygowania ryzyka” (12,1%) oraz “szybszego czasu reakcji na awarie” (18,2%) sugeruje, że firmy wciąż traktują agenty jako technologię “beta”. Obawiają się powierzać im zadania krytyczne dla bezpieczeństwa lub stabilności firmy (np. automatyczne reagowanie na cyberataki), preferując zastosowania, gdzie błąd agenta ma mniejsze konsekwencje. Tą tezę potwierdza też inna obserwacja, do której za chwilę dojdziemy.
Badanie burzy też stereotypowy obraz agenta AI jako “coding assistant” wykorzystywany w vibe codingu lub chatbot obsługi klienta, pokazując obecność agentów w 26 różnych domenach. Tutaj, znając ogólne wydarzenia na rynku i to jak firmy podchodzą do wdrożeń i adopcji nowych technologii nie ma niespodzianek (może poza tym ostatnim punktem):
- Finanse i Bankowość (39,1%): Sektor ten jest liderem adopcji. Agenty są tu wykorzystywane do analizy dokumentów kredytowych, wykrywania anomalii w transakcjach (AML – Anti-Money Laundering) oraz przygotowywania raportów rynkowych. Presja na automatyzację w bankowości jest ogromna ze względu na wolumeny danych i regulacje.
- Technologia (24,6%): Obejmuje to nie tylko pisanie kodu, ale także zarządzanie infrastrukturą chmurową (DevOps/SRE) oraz wsparcie techniczne produktów.
- Usługi Korporacyjne (23,2%): Działy HR (rekrutacja, onboarding), działy prawne (analiza umów) i administracja.
- Nauka i R&D (11,6%): Agenty w laboratoriach chemicznych i biomedycznych, przyspieszające przegląd literatury i projektowanie eksperymentów.
Długi ogon “innych” zastosowań (15,9%) obejmuje tak niszowe obszary jak logistyka, rolnictwo czy edukacja.
Kluczowym odkryciem badania jest profil użytkownika końcowego. 92,5% wdrożonych agentów obsługuje ludzi, a nie inne systemy. Co więcej, ponad połowa (52,2%) to systemy skierowane do użytkowników wewnętrznych (pracowników firmy)… bo wiadomo, reputacja i brak zaufania. Strategia “Safe Launch” – wybór użytkownika wewnętrznego jest świadomą strategią zarządzania ryzykiem.
Warta odnotowania jest jeszcze jedna obserwacja: w rozwiązaniach technicznych doąży się doptymalizacji czasu odpowiedzi i “urywania” kolejnych milisekund. Tymczasem w przypadku w/w wdrożeń agentów AI obserwujemy odwrotny trend. 66% systemów produkcyjnych toleruje czasy odpowiedzi rzędu minut, a nawet godzin. Ten “paradoks latencji” wynika z natury zadań, które agenty przejmują. Jeśli agent analizuje skomplikowaną szkodę ubezpieczeniową, zajmuje mu to np. 5 minut. Dla człowieka to samo zadanie zajmuje 2 godziny lub 2 dni robocze. W tym kontekście, 5 minut oczekiwania na wynik agenta jest wciąż wzrostem wydajności o rzędy wielkości.
Firmy świadomie poświęcają szybkość na rzecz jakości. Pozwalają agentowi na wykonanie większej liczby kroków weryfikacyjnych, ponieważ poprawność jest ważniejsza niż natychmiastowa odpowiedź. Wyjątkiem są systemy głosowe (voice bots), gdzie opóźnienia powyżej sekundy są nieakceptowalne dla użytkownika – tam walka o latencję jest kluczowym wyzwaniem.
Jak powstają działające systemy?
Wyniki tutaj są szczególnie interesujące, ponieważ pokazują ogromny rozdźwięk między tym, co jest modne w tutorialach na YouTube i pracach naukowych, a tym, co organizacje wdrażają na serwery produkcyjne.
W romantycznych wizjach szefów firm agenty AI są w pełni autonomiczne – dostają cel (“zwiększ sprzedaż”) i same wymyślają plan. Rzeczywistość produkcyjna jest inna…
Po pierwsze static workflows – 80% badanych przypadków używa zdefiniowanych z góry ścieżek działania. Agent nie “wymyśla” procesu. Porusza się po zaprojektowanej ścieżce, podejmując decyzje tylko w węzłach decyzyjnych (np. zadania klasyfikacyjne – czy ten dokument jest kompletny)
Po drugie limit kroków – 68% agentów wykonuje maksymalnie 10 kroków autonomicznych przed wymaganą interwencją człowieka lub zakończeniem zadania. Do tego dochodzi brak nieskończonych pętli, gdzie celem jest agresywne ograniczenie liczby wywołań modeli ze względu na koszty (46,7% agentów wykonuje mniej niż 5 wywołań modelu na zadanie).
Wniosek: Biznes woli “głupszego” agenta, który działa przewidywalnie, niż “genialnego”, który może wpaść w nieskończoną pętlę wydawania cały budżet na API. Z drugiej strony za taką pętle można dostać od Open AI nagrodę … chociaż oczywiście to nie jest powód do dumy…
Wracając do raportu – badanie pokazuję zaskakującą statystykę: 70% systemów produkcyjnych nie używa fine-tuningu. Wdrożone systemy opierają się wyłącznie na gotowych modelach (Off-the-Shelf), takich jak OpenAI GPT, Claude Sonnet czy Gemini. Firmy wybierają najpotężniejsze dostępne modele, ponieważ koszt ich użycia (nawet wysoki) jest i tak znikomy w porównaniu do kosztu pracy eksperta, którego agent wspomaga. Fine-tuning jest stosowany głównie tam, gdzie trzeba zmusić model do bardzo specyficznego zachowania lub ze względów regulacyjnych/kosztowych używa się mniejszych modeli open-source (np. Llama 3) we własnej infrastrukturze.
Kolejna ciekawostka manualne prompty – w świecie naukowym dużą popularność zdobywają frameworki takie jak DSPy, które automatyzują tworzenie promptów, traktując je jak problem optymalizacyjny. Jednak w badaniu, tylko 8,9% wdrożeń korzysta z optymalizatorów promptów. Dlaczego ręczne pisanie promptów (79%) wciąż króluje – ta część jest dość łagodnie potraktowana, ale poszukałbym tutaj drugiego dna. W raporcie pojawia się:
- Kontrolowalność – inżynierowie chcą wiedzieć dokładnie, co wchodzi do modelu. Automatycznie wygenerowane prompty bywają nieczytelne – ok, można się z tym zgodzić…
- Debugowanie – kiedy system zawodzi, łatwiej poprawić zdanie w instrukcji napisanej przez człowieka niż analizować skomplikowany, wygenerowany łańcuch – to już trochę mniej do mnie przemawia
- Skomplikowanie instrukcji – prompty produkcyjne są ogromne. 12% systemów używa instrukcji przekraczających 10 000 tokenów. Zawierają one całe podręczniki operacyjne, przykłady brzegowe (few-shot) i schematy danych – a to brzmi jak wymarzony obszar dla optymalizatorów.
Podsumowując – raport tego nie podejmuje, ale myślę, że główny powód to brak wiedzy i doświadczenia w tym obszarze (pewnie też oszczędności), wśród zespołów wdrażających.
Trochę w tym samym kontekście można potraktować kolejny obszar. Brak wykorzystania framworków jak LangChain i budowa rozwiązań In-House. Ankieta ogólna (obejmująca prototypy) pokazuje dużą popularność LangChain (25%) i CrewAI (10,7%), Jednakże, analiza 20 case studies pokazuje drastycznie inny obraz: 85% zespołów produkcyjnych buduje własne rozwiązania in-house od zera, rezygnując z gotowych frameworków.
Argumenty i przyczyny odrzucenia frameworków w produkcji są mało przekonujące i chyba potwierdzają wcześniej postawioną tezę na temat wiedzy i doświadczenia. W badaniu mówi się o:
- Nadmiarze abstrakcji (Abstraction Hell) – Frameworki ukrywają logikę wywołań API itp. oraz konieczność obsłużenia konkretnych błędów, w czym mają frameworki przeszkadzać.
- Trudności z debugowaniem – gdy agent oparty na framework powoduje błędy, developer musi debugować nie tylko swój kod, ale i kod biblioteki.
- Prostota potrzeb – większość agentów produkcyjnych to w rzeczywistości proste pętle while z kilkoma instrukcjami if, wywołujące API modelu. Do tego nie potrzeba ciężkich bibliotek…
Ok, nie znam szczegółów wdrożeń… zostawmy to w takim razie bez komentarza.
Natomiast warto wspomnieć że większość omawianych systemów korzysta z mechanizmu RAG (Retrieval-Augmented Generation), czyli dostarczania modelowi zewnętrznej wiedzy. Raport wskazuje na ewolucję z “Standard RAG” do “Agentic RAG”.
Jak zmierzyć jakość agenta i wdrożenia?
Docieramy do najtrudniejszej koncepcyjnie części, gdzie czeka nas kilka niespodzianek.
Już na początku wybrzmiewa dominacja metody “Human-in-the-Loop”. Ze względu na brak zaufania do automatycznych metryk, 74% wdrożonych systemów polega na ocenie ludzkiej. Może to przybierać dwie formy:
- Offline (Podczas rozwoju) – zespoły tworzą Golden Datasets – pary pytań i idealnych odpowiedzi. Eksperci dziedzinowi (lekarze, prawnicy) ręcznie oceniają odpowiedzi agenta przed wdrożeniem nowej wersji.
- Online (Weryfikacja w czasie rzeczywistym) – w systemach o wysokim ryzyku, agent nie wykonuje akcji końcowej. Przygotowuje draft, który człowiek musi zatwierdzić. Np. agent generuje odpowiedź na reklamację, ale przycisk “Wyślij” klika człowiek po przeczytaniu.
A co z wykorzystaniem LLM-as-a-Judge? Tutaj pojawia się informacja, że 52% zespołów stosuje tę technikę. Polega ona na użyciu bardzo silnego modelu do oceniania odpowiedzi generowanych przez agenta. Badanie podkreśla jednak, że zespoły produkcyjne nigdy nie ufają modelowi w 100%. Jest on używany jako sito wstępne lub do monitorowania trendów, ale krytyczne decyzje są weryfikowane przez ludzi. Z tą strategią można i należy się zgodzić, modele-sędziowie mają swoje wady, takie jak “verbosity bias” (preferowanie dłuższych odpowiedzi, nawet jeśli są laniem wody).
Na konieć tej części słowo o benchmarkach. Publiczne benchmarki (jak MMLU, HumanEval) są w produkcji praktycznie bezużyteczne, ponieważ testują ogólną wiedzę, a nie specyficzne zadania biznesowe. Dlatego 25% zespołów buduje własne benchmarki od zera, co jest procesem kosztownym i czasochłonnym. Pozostałe 75% działa “na wyczucie”, polegając na testach A/B i feedbacku użytkowników, co stanowi duże ryzyko operacyjne…
Kilka dodatkowych punktów i podsumowanie
Kilka luźnych punktów:
Raport jednoznacznie wskazuje na Niezawodność (Reliability) jako głównego przeciwnika wdrożeń. Z badań wynika, że ryzyko halucynacji, wpadania w pętle itp. rośnie wykładniczo wraz z liczbą kroków. Jeśli pojedynczy krok modelu ma 95% skuteczności, to agent wykonujący 10 kroków ma szansę na sukces wynoszącą tylko około 60%. To matematyczne ograniczenie wymusza stosowanie prostych, krótkich procesów.
Bezpieczeństwo (Security) jest zarządzane głównie przez architekturę, a nie przez same modele. Agenty są podatne na ataki typu Prompt Injection. W odpowiedzi, inżynierowie stosują często sandboxing np. z wykorzystaniem Dockera, bez dostępu do sieci wewnętrznej firmy oraz domyślny tryb Read-Only, gdzie wiele agentów ma tylko prawo odczytu danych, bez możliwości ich modyfikacji w systemach produkcyjnych.
Istnieje wyraźny rozdźwięk między tym, co dzieje się na uczelniach (np. poszukiwanie pełnej autonomii, skomplikowane algorytmy samouczenia), a tym, co dzieje się w firmach (poszukiwanie stabilności, proste prompty, sztywne reguły). Inżynierowie w 2025 roku wolą budować proste, “łatwe” systemy, które łatwo jest kontrolować i przeprowadzić debugowanie.
Podsumowując – warto zapoznać się z tym badaniem. Pokazuje jak bardzo daleko sięga świat akademicki i jak brutalnie racjonalny i często nieskomplikowany (słowo “opóźniony” może byłoby nawet bardziej na miejscu) jest świat biznesu, który z drugiej strony przez swoją pragmatyczność detronizuje w jakiś sposób całe to Agentowe zamieszanie. Oczywiście mam świadomość, że do biznesu może często nawet nie docierać informacja o pełnych możliwościach jako ofertują nowe algorytmy i modele. Z drugiej strony obszar badawczy oznacza często bardzo wysokie, nieracjonalne (z perspektywy biznesu) ryzyko, którego biznes za wszelką cenę chcę uniknąć – i to jest chyba najlepsze podsumowanie.
Linki i źródła:
- Link do raportu: https://arxiv.org/abs/2512.04123v1
- DSPy: https://dspy.ai/ oraz np. https://www.ibm.com/think/topics/dspy
- Link do raportu MIT Media Lab and NANDA Initiative. The internet of ai agents. https://web.archive.org/web/20250818145714/https://nanda.media.mit.edu/ai_report_2025.pdf z jakiegoś powodu oryginalny link https://nanda.media.mit.edu/ nie działa.



