Często podczas analizy raportów z badań robię sobie sporo notatek związanych z raportem. Nie ukrywam, że panuje w nich dużych chaos i z jednej strony, aby to usystematyzować, a z drugiej aby jednak nadać temu bardziej czytelny charakter , postanowiłem to zamknąć w formie takiego podsumowania. Poniżej zredagowane notatki. Jeżeli komuś się przyda – zapraszam do korzystania.
Może zaczniemy od ogólnej obserwacji, na podstawie komentarzy na X, HuggingFace i innych portalach. DeepSeek staje się powoli taką formą “religii ” w świecie LLM (albo nawet szerzej ML), z pokaźną grupą wyznawców na całym świecie. Trudno jest czasami dyskutować z fanami DeepSeek’a. Oczywiście nie bierze się to znikąd. DeepSeek swoimi pomysłami badawczymi, raportami z badań i publikacją (chociaż częściowych źródeł) miał (i nadal ma) duży wpływ na demokratyzację dostępu do dużych modeli językowych i rozwój otwartych, dostępnych rozwiązań. Zaryzykuję tezę, że trend dot. lokalnych małych modeli LLM, który w ostatnim czasie jest coraz mocniejszy, nie byłby możliwy bez jakościowych publikacji m.in. DeepSeeka. Zabawne jak ograniczenia kolejny raz spowodowały nowy impuls do rozwoju technologicznego (trochę przypomina to historię Windows vs. Linux), tylko tym razem “otwarte” kojarzy się z Chinami, a zamknięte… no cóż – czas na analizę.
Otwarte vs. Zamknięte – czyli ewolucja i rosnąca przepaść
Do niedawna panowało przekonanie, że modele otwarte (open-source), rozwijane przez społeczność naukową i niezależne laboratoria, powoli ale z sukcesami zbliżają się do możliwości modeli zamkniętych, tworzonych przez gigantów technologicznych (Open AI, Google czy Anthropic). Badacze jednak już na początku odzierają nas z tego wrażenia, stawiając trzeźwą diagnozę: zamiast konwergencji, obserwujemy zjawisko dywergencji. Przyśpieszenie rozwoju modeli GPT-5, Gemini 3.0 pro, czy Claude 4.5 powoduje, że luka wydajnościowa między modelami zamkniętymi a otwartymi, zaczęła się niebezpiecznie rozszerzać. Widać to szczególnie w domenach wymagających głębokiego rozumowania wieloetapowego, zaawansowanej inżynierii oprogramowania czy autonomicznego działania agentowego.
DeepSeek zidentyfikował trzy obszary, które działają jak “szklany sufit” dla dotychczasowych architektur open-source:
- Ograniczenia architektury transformera – architektura transformera, oparta na mechanizmie standardowej uwagi (Vanilla Attention) przy sekwencjach przekraczających 100 000 tokenów powoduje, że koszt przetwarzania staje się zaporowy – to uniemożliwia efektywne skalowanie oraz skuteczny post-trening na długich sekwencjach rozumowania.
- Alokacji zasobów treningowych – tutaj tradycyjne założenie mówi, że większość budżetu obliczeniowego powinna być przeznaczona na fazę pre-treningu, czyli “czytanie Internetu”, a DeepSeek sugeruje, że modele otwarte mają problem zasobowy z fazą post-treningu, w której model uczy się specyficznych umiejętności rozumowania i rozwiązywania problemów z wykorzystaniem Reinforcement Learningu.
- Ograniczenia w systemach agentowych – modele otwarte są mniej wydajne w obszarze agentowym, dotoczy to przede wszystkim umiejętności posługiwania się toolami i podążania za złożonymi instrukcjami, co wynika z braku odpowiednio zróżnicowanych i skalowalnych danych treningowych.
W odpowiedzi na te ograniczenia DeepSeek proponuje nową architekturę, która ma przełamać te barier:
- DeepSeek Sparse Attention (DSA): czyli zmiana mechanizmu uwagi, redukująca złożoność obliczeń i pamięci, umożliwiająca obsługę ekstremalnie długich kontekstów bez degradacji jakości
- Skalowalny Framework RL i stabilizacja GRPO: protokół optymalizacji polityki, który pozwala na stabilne trenowanie modelu przy użyciu znacznie większych zasobów obliczeniowych w fazie post-treningu, osiągając budżet przekraczający 10% kosztów pre-treningu.
- Pipeline syntezy zadań agentowych (Large-Scale Agentic Task Synthesis Pipeline): system generowania danych treningowych, który pozwala modelowi na naukę poprzez symulację interakcji w dużą liczbą syntetycznych środowisk
Ok, poznajmy bliżej te trzy propozycje:
DeepSeek Sparse Attention (DSA)
Najpierw krótkie wprowadzenie: w modelu Transformer, mechanizm uwagi (Self-Attention) pozwala każdemu tokenowi w sekwencji “spojrzeć” na każde inne słowo (token), aby zbudować kontekst. Jeśli zdanie ma długość \(L\), model musi wykonać \(L^2\) operacji porównania.
- Dla krótkiego akapitu (1000 tokenów): \(10^6\) (1 mln) operacji. Jeszcze zarządzalne.
- Dla książki (100 000 tokenów): \(10^{10}\) (10 mld) operacji. A to już jest kosztowne.
- Dla repozytorium kodu lub długiej historii czatu (128 000+ tokenów): Koszt rośnie lawinowo, zużywając pamięć GPU i drastycznie spowalniając generowanie odpowiedzi.
Najpopularniejsze próby rozwiązania tego problemu opierały się na sztywnych regułach, gdzie model mógł patrzeć tylko np. na 100 słów wstecz (Sliding Window) lub na co określone słowo (Strided Attention). Metody te były szybkie, ale mówiąc wprost – niezbyt mądre i wpływały znacznie na efektywność modelu. Model tracił wiele kluczowych informacji, jeśli znajdowały się one poza wyznaczonym oknem lub nie trafił w odpowiedni zestaw słów.
DSA wprowadza koncepcję dynamicznej, sterowanej treścią uwagi. Zamiast narzucać modelowi sztywne ramy (“patrz tylko na sąsiadów”), DSA pozwala modelowi każdorazowo decydować które fragmenty treści są istotne. Architektura ta składa się z dwóch współpracujących modułów, które można porównać do procesu pracy badacza w archiwum.
Naszym badaczem jest tutaj Lightning Indexer. Jest to mechanizm wstępnej selekcji. Lightning Indexer to lekka sieć neuronowa wstępnie oblicza “wynik przydatności” dla każdego nowego tokena. Po otrzymaniu wyników z Indexera, następuje właściwy proces uwagi. Mechanizm wybiera określoną liczbę bloków o najwyższym wyniku (Top-k). Tylko dla tych wybranych fragmentów uruchamiana jest “ciężka”, precyzyjna uwaga. Cały proces jest dokładnie omówiony w badaniu – warto to przeanalizować.
Od razu warto wspomnieć, że DeepSeek nie porzuca Multi-Head Latent Attention (MLA). Nadal wykorzystywana jest tutaj ta technika kompresji KV cache, która pozwala istotnie ograniczyć zapotrzebowania na VRAM.
W wersji 3.2, DSA działa w trybie MQA (Multi-Query Attention), co oznacza, że wyselekcjonowane przez Indexer klucze i wartości są współdzielone przez wiele “głów” uwagi (MLA). W badaniu podkreśla się, że ta synegria (DSA + MLA) sprawia, że model 3.2 jest obecnie jednym z najwydajniejszych modeli pod względem stosunku wydajności do zasobów sprzętowych.
Warto zajrzeć tutaj też do samego procesu treningu i adaptacji opisanego w raporcie dwuetapowego procesu: Dense Warm-up i Sparse Training.
Post-Trening: Skalowanie RL i Stabilizacja GRPO
Standardowe podejście RL, dokłądnie PPO (Proximal Policy Optimization), jest dość wymagające w skalowaniu, głównie ze względu na konieczność utrzymania w pamięci modelu oceniającego (value model), czyli modelu krytyka dla aktualnie trenowanego modelu. Wykorzystanie tej strategii powstaje konieczność praktycznie podwojenia ilości wymaganej pamięci. DeepSeek wykorzystuje tutaj już algorytm GRPO (Group Relative Policy Optimization), który eliminuje potrzebę modelu krytyka. Strategia tutaj jest prosta: dla każdego pytania generuje grupę odpowiedzi (np. 8 lub 16) i ocenia je względem siebie nawzajem. Odpowiedź lepsza niż średnia grupy jest nagradzana, gorsza karana. Jest to znacznie bardziej efektywne pamięciowo niż oddzielny model krytyka.
Jednak tutaj pojawił się problem ze stabilnością numeryczną, o której wspomina raport. Ta część jest dość skomplikowana i na ile rozumiem w momencie gdy model przypisuje bardzo niskie prawdopodobnieństwo tokenom, które w poprzednim cyklu miały wysokie prawdopodobieństwo, następuje destabilizacja estymatora i gradienty aktualizujące wagi wracają z wartościami bardzo przypadkowymi. Tutaj został zastosowany Unbiased KL Estimate (nieobciążony estymator KL?), który wykorzystuje potrafi skorygować obliczenia i w przypadku jw produkuje stabilniejsze gradienty.
Jeszcze jedną ciekawostką jest wykorzystanie Off-Policy Sequence Masking, aby zapobiegać efetowi opóźnienia między starą a nową polityką w procesie generowania danych. To zjawisko występuje w dużych systemach i dotyczy opóźnienia między momentem wygenerowania danych przez model (stara polityka), a momentem ich użycia do treningu (nowa polityka). Jeśli model zmieni się zbyt mocno w międzyczasie, dane stają się nieaktualne (off-policy). Uczenie się na “starych błędach”, których nowy model by już nie popełnił może zatrzymać postęp uczenia. DeepSeek wprowadził mechanizm maskowania: jeśli różnica między starą a nową polityką dla danej próbki jest zbyt duża, i próbka ta ma negatywną ocenę (czyli jest błędem), jest ona maskowana.
Ostatnie w tym bloku są dwie sekcje Keep Routing i Keep Sampling Mask. Modele typu MoE (Mixture-of-Experts), używają routera do kierowania tokenów do różnych ekspertów. Keep Routing podczas treningu wymusza się, aby tokeny trafiały do tych samych ekspertów, co podczas generowania danych. Keep Sampling Mask zachowuje maskę jeśli podczas generowania użyto techniki Top-p (odrzucenie mało prawdopodobnych słów), to ta sama maska jest stosowana podczas obliczania błędu.
Large-Scale Agentic Task Synthesis Pipeline
DeepSeek 3.2 łączy zdolności głębokiego rozumowania z użyciem narzędzi. Wcześniejsze modele, miały tendencję do traktowania myślenia i działania jako rozłącznych procesów.
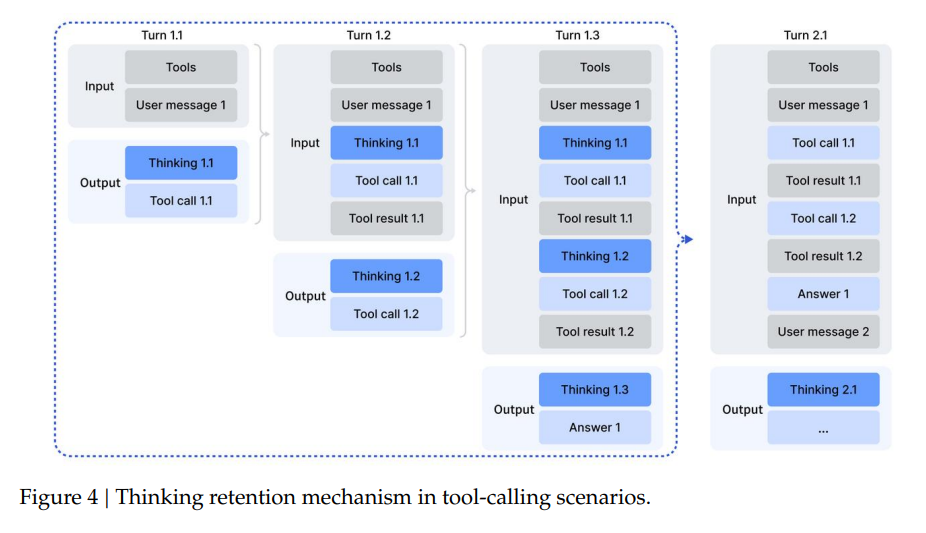
Standardowe podejście w modelach agentowych polegało na tym, że po wywołaniu narzędzia (np. obliczenie matematyczne), model zapominał swój wcześniejszy proces myślowy (CoT), otrzymując jedynie wynik działania narzędzia. Wymuszało to ponowną analizę problemu od zera w każdym kroku. W przypadku 3.2 model zachowuje blok myślowy w swojej pamięci roboczej tak długo, jak trwa interakcja z narzędziami. Kontekst jest czyszczony dopiero wtedy, gdy pojawi się nowa instrukcja.
Badanie wspomina też o fazie cold-start. Model najpierw nauczono podstawowej strategii “Najpierw pomyśl, potem wywołaj narzędzie”. Użyto do tego starannie przygotowanych promptów (zaprezentowanych w załącznikach do raportu).
W sekcji Large-Scale Agentic Tasks pojawia się omówienie agentów zaimplementowanych w ramach modelu 32.
Podsumowanie
Wyników i benchmarków nie będę analizował w jakiś dokładny sposób, to oczywiście ważny element raportu, ale one mają w pewnym sensie chwilowe znaczenie. Warto jedynie może wspomnieć, że w benchmarkach pokazany został nowy model “Speciale”, który wg raportu wyprzedził zamknięte modele GPT-5 High i Gemini 3.0 pro w benchmarkach matematycznych (tabela poniżej). Wynik 99.2% w HMMT Feb 2025 robi wrażenie.
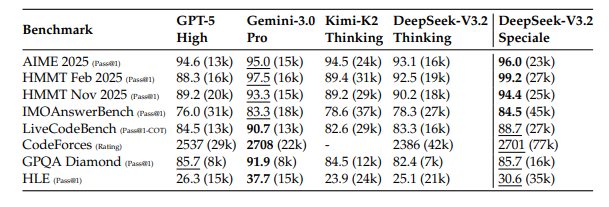
Wariant Speciale jest modelem wysokokosztowym. Główna różnica leży w strategii treningu RL, gdzie zmniejszono karę za długość odpowiedzi. Model mógł bez ograniczeń korzystać z procesu myślenia i generowania tokenów sekcji think (w normalnym treningu model jest karany za zbyt długie odpowiedzi).
W kontekście modelu Speciale, to otwiera trochę nowy kierunek – Intelligence Density. Celem jest sprawienie, aby model osiągał zbliżone wyniki, do wersji Speciale, ale przy użyciu krótszych łańcuchów myślowych. Będzie to wymagało destylacji wiedzy z “długo myślących” modeli do bardziej zwięzłych form, co stanowi kolejną granicę, którą DeepSeek chce pokonać…
Linki i źródła
- HuggingFace: https://huggingface.co/deepseek-ai/DeepSeek-V3.2
- Raport techniczny: https://huggingface.co/deepseek-ai/DeepSeek-V3.2/resolve/main/assets/paper.pdf
- Api: https://api-docs.deepseek.com/news/news251201
- Wersja eksperymentalna modelu DeepSeek-v3.2-exp: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp